Cerebras-GPT: Transforming Enterprise AI with Compute-Efficient Large Language Models
Cerebras-GPT: Transforming Enterprise AI with Compute-Efficient Large Language Models
Estimated reading time: 7 minutes
Key Takeaways
- Cerebras-GPT delivers state-of-the-art accuracy while minimising compute costs.
- Seven open models let enterprises fine-tune intelligence for their specific domains.
- A unique hardware architecture removes the pain of multi-GPU scaling.
- Real-world benchmarks show up to 8× efficiency gains over traditional stacks.
- Open licensing accelerates innovation and future-proofs AI investments.
Introduction
Enterprises are drowning in data yet starving for insight. Modern organisations require enterprise-first NLP solutions that scale economically. This is precisely where Cerebras-GPT enters the scene.
The family of open, compute-efficient language models shifts the cost–accuracy curve, empowering teams to iterate quickly, deploy safely, and innovate boldly.
“Compute efficiency is not a luxury; it is the currency that buys faster time-to-insight.”
Model Range
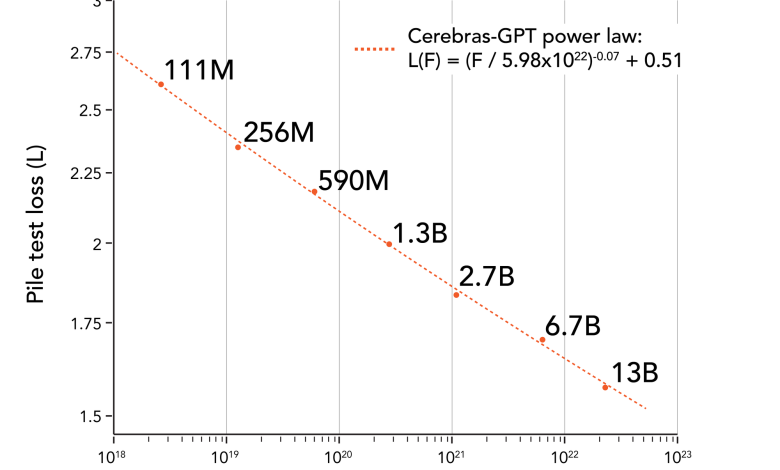
Cerebras offers seven GPT variants, from a nimble 111 M parameters to a robust 13 B. This spectrum lets businesses pick the right capacity for the job—no more over-provisioning.
- 111 M – 590 M: Ideal for lightweight text analytics.
- 1.3 B – 6.7 B: Balanced power for chatbots and document summarisation.
- 13 B: Premium choice for deep reasoning and code generation.
Training follows the Chinchilla formula, ensuring every GPU hour translates into maximum accuracy.
Performance Edge
The secret sauce is hardware–software co-design. Cerebras’s monolithic Wafer-Scale Engine streams weights efficiently, eliminating the network chatter that slows GPU clusters.
Headline numbers speak loudly:
- Up to 3 000 tokens / s on 120 B-parameter workloads.
- 8 × tokens-per-dollar versus conventional cloud GPUs.
- Linear scaling from prototype to production.
Reviewers praised the blazing inference speed that makes real-time enterprise chatbots finally feasible.
Enterprise Gains
Deploying Cerebras-GPT pays dividends across the organisation:
- Lower Op-Ex: Fewer servers, smaller energy bills.
- Rapid fine-tuning: Iterate in hours, not weeks.
- Compliance-ready: On-prem options keep data sovereign.
- Future-proof: Same stack will support trillion-parameter successors.
These wins rest on the world-record inference speeds proven in production workloads.
Use Cases
Across industries, Cerebras-GPT is already unlocking new value streams:
| Sector | Application | Outcome |
|---|---|---|
| Finance | Risk modelling & trade strategy generation | Milliseconds decision loops |
| Healthcare | Clinical note summarisation | Reduced admin time by 40 % |
| Technology | Code completion & QA | Release cycles shortened |
A recent deployment leveraged the predictive power of GPT-J to slash customer ticket resolution times.
Future Path
Where does Cerebras go next? Three vectors are already visible:
- Scaling: Road-maps hint at 1 T-parameter models on a single wafer.
- Openness: Continued release of fully open checkpoints fosters community trust.
- Turn-key stacks: Push-button deployment modules for major cloud and on-prem environments.
Together these efforts democratise advanced AI, ensuring innovators—not just mega-corps—can harness large language models.
Conclusion
Cerebras-GPT redefines the economics of large language models. By marrying compute-optimal training with radical hardware innovation, it places frontier-grade AI within reach of every enterprise. The organisations that act today will lead tomorrow.



